
本地化AI部署现在确实到了一个新的阶段,以前大家觉得这是大厂才玩得起的赛道,现在开发者个人、科研小组、甚至几个人的小工作室都在琢磨怎么把模型跑在本地。需求是真的上来了,但落地的时候问题也不少,配环境、调驱动、装依赖,每一个环节都能卡住半天。技嘉这次拿出来的AI TOP ATOM线上股票配资专业,切的就是这个口子。

这款机器采用的是银灰色金属外壳,表面做了细磨砂处理,质感比较内敛,没有花哨的灯效,整体看起来更像一台专业的仪器而非消费电子产品。150mm见方,厚度50.5mm,放在桌面上比常规的Mini ITX主机小一圈,比很多路由器还紧凑。拿起来掂量一下,1.2公斤左右,单手能拎走。接口集中在背部,包括三个USB 3.2 Type-C、一个HDMI 2.1a、一个万兆RJ-45网口,还有一个比较特别的NVIDIA ConnectX-7接口,这个接口可以用来直连另一台AI TOP ATOM,实现算力和显存的池化。散热出风口设计在正面和一侧,横栅格的开孔方式既能保证通风量,运行时噪音控制得也比较好。

拆开外壳看内部,这台机器的核心是NVIDIA GB10 Grace Blackwell芯片,采用了CPU和GPU一体封装的设计。GB10基于台积电3nm工艺,功耗控制在140W左右,这才能在这么小的机身里塞进去高性能算力。GPU部分内置了6144个CUDA核心,数量上和消费级的RTX 5070相当,但因为采用了统一内存架构,它能够访问128GB的LPDDR5x内存,CPU和GPU之间通过NVLink-C2C互联,双向带宽远超传统PCIe通道,消除了数据拷贝的瓶颈。这对于运行大模型来说至关重要,显存墙的问题在这里基本不存在了。

在FP4低精度计算格式下,这台机器能释放出1000 TOPS的算力,官方数据是可以支持高达2000亿参数的模型运行。内存带宽达到273GB/s,搭配最高支持4TB的Gen5 SSD,整个数据读取和模型加载的吞吐能力都比较可观。
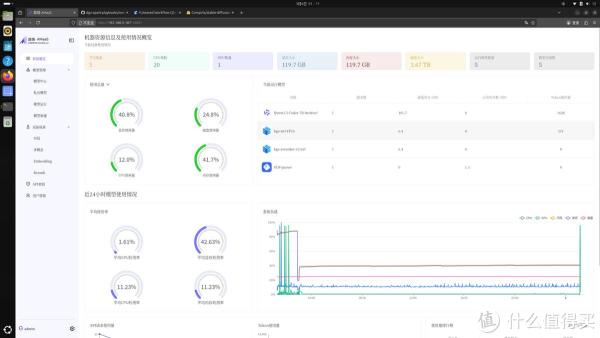
实际使用层面,技嘉和趋境科技合作预装了一套完整的软件环境,开箱之后不需要手动配置CUDA、Python环境或者下载模型依赖,这一点对于很多刚接触AI开发的人来说很友好。系统基于Ubuntu底层做了图形化界面改造,浏览器输入本机IP加端口号就能进入AMaaS管理后台。后台仪表盘可以实时看到GPU负载、显存占用和Tokens消耗量,模型管理界面里已经预置了智谱GLM-4.5-Air 106B大模型,如果需要替换成其他模型,比如Qwen 2.5-7B,也可以在私有模型页面导入,只要把模型文件放到指定目录,配置好参数就能跑起来。
在趋境智问应用平台上,集成的功能覆盖了比较多的日常场景。AI对话界面支持多轮上下文理解,响应速度很快,生成文本的质量在专业领域表现不错,虽然对特别冷门的知识点覆盖还有提升空间,但作为日常知识库查询和学习辅助工具已经够用。办公助手板块里包含了周报生成、文章校对、语气润色、会议纪要整理这些功能,操作都是图形化点选,不需要写提示词模板。AI阅读支持多种文档格式上传,自动生成摘要和重点提取,翻译辅助功能也能减少跨语言阅读的障碍。
长文写作模块值得多说一句,它最大的价值在于解决从零到一的问题。智能大纲生成逻辑比较清晰,对于需要快速产出标准化内容的人来说,可以省去不少构思时间。当然,生成的内容目前还是偏模板化,深度和独特性需要人工二次调整,但作为初稿已经足够实用。
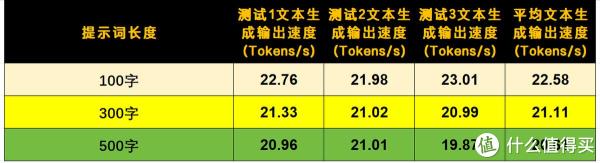
并行任务处理方面,同时启动GLM-4.5-Air对话、Embedding向量化和Rerank重排序三个实例时,系统资源分配比较均衡,互不干扰。这意味着单台设备就能搭起完整的RAG检索增强生成链路,不需要在多台服务器之间折腾。在模型推理速度测试中,GLM-4.5-Air 106B模型在100字提示词下输出速度约22.5 Tokens/s,300字时约21.1 Tokens/s,500字时约20.6 Tokens/s,这个表现在桌面级设备里属于优秀水准。并发处理不超过4个线程时,速度基本能维持在10 Tokens/s以上,超过4线程会有明显下降,但对于这种体积和功耗的设备来说已经可以接受。
显存占用方面,直接跑GLM-4.5-Air的FP8原始模型会出现爆显存,换成NVFP4量化模型后,占用稳定在68-69GB,106B模型运行流畅,128GB统一内存的优势在这里体现得比较充分。而对于有更高并行需求的用户,可以通过NVIDIA ConnectX-7接口直连另一台AI TOP ATOM,把两台机器的算力和显存池化,能够支撑超4000亿参数的大模型运行,这种拼接扩展的方式比一次性投入大型服务器要灵活,成本门槛也低不少。

总体来说线上股票配资专业,技嘉AI TOP ATOM解决的是私有化AI部署的两个核心问题:一是硬件算力密度,在桌面级体积内做到了千亿参数模型的流畅运行;二是软件上手门槛,图形化管理和预置模型让部署时间从几天缩短到几分钟。对于AI开发者、科研人员、小型工作室,或者对数据隐私有严格要求的企业来说,这套方案提供了一个比较完整的本地化AI基础设施。它让原本需要机房级配置才能跑起来的算力,真正落到了办公桌上。
康乾配资提示:文章来自网络,不代表本站观点。
相关文章



热点资讯





